OptOSS AI v.10.1 - Release
OptOSS AI v10.1 introduces new powerful AI-driven capabilities for cybersecurity operations, root cause analysis, monitoring, and operational efficiency.
.png)
OPT/NET
June 1, 2026
.jpeg)
With increasing reliance on digital giants who deliver to us all cloud services, massive internet outages have become more frequent.
Uptime Institute’s 2022 outage analysis finds that downtime costs and consequences are worsening, and that networking issues are among the main causes of IT outages. The massive service outages are a stark and persistent reminder that big tech giants should keep the infrastructure firmly under control. However, larger and longer Internet outages are becoming more impactful and disturbing. Internet outages and blackouts do not only affect home users on the fixed networks, but they can occur on a much wider scale and impact mobile and traditional voice communications and even emergency call centres, causing severe problems for an entire region or country.
The leader of 2021 among global outages was undoubtedly the seven-hour shutdown of Meta services (Facebook, Instagram, WhatsApp), which occurred on October 4 and affected hundreds of millions of users in the company's corporate partner client base. The site Downdetector, which monitors network outages, recorded over 10 million problem reports. Lucky for us users, Facebook stated that “the root cause of this outage was a faulty configuration change” and that there is “no evidence that user data was compromised as a result” of the outage.
In 2022, a series of high-profile Internet outages further demonstrated our world's dependence on cloud and telecom service providers, as well as the fragility of an increasingly overburdened infrastructure. Let's take a look at some of the other most notorious outages and downtimes this year.
On June 21, 2022, Cloudflare experienced an outage that affected traffic in 19 data centres. The outage significantly impacted internet access for many apps that depend on it to deliver content to users around the world, including FTX, Shopify, Fitbit, Discord, Omegle, DoorDash, Crunchyroll, NordVPN, and Feedly.
According to Cloudflare's official post, this outage was caused by a change that was part of a long-term project to improve resiliency of the service in the busiest places (which is quite ironic). When running the update code, a network configuration code error affected the sequence of BGP (Border Gateway Protocol) network routing protocol advertisements, and a misconfiguration in the diff format changed the order of terms in the BGP list of prefixes, stopping the advertisement of network reachability information by itself, and hence removing access to the affected locations, which prevented servers all over the world from contacting the origin servers. This misconfiguration of the router prevented the correct IP routes from being advertised, thus preventing traffic from properly passing through to the Cloudflare infrastructure.
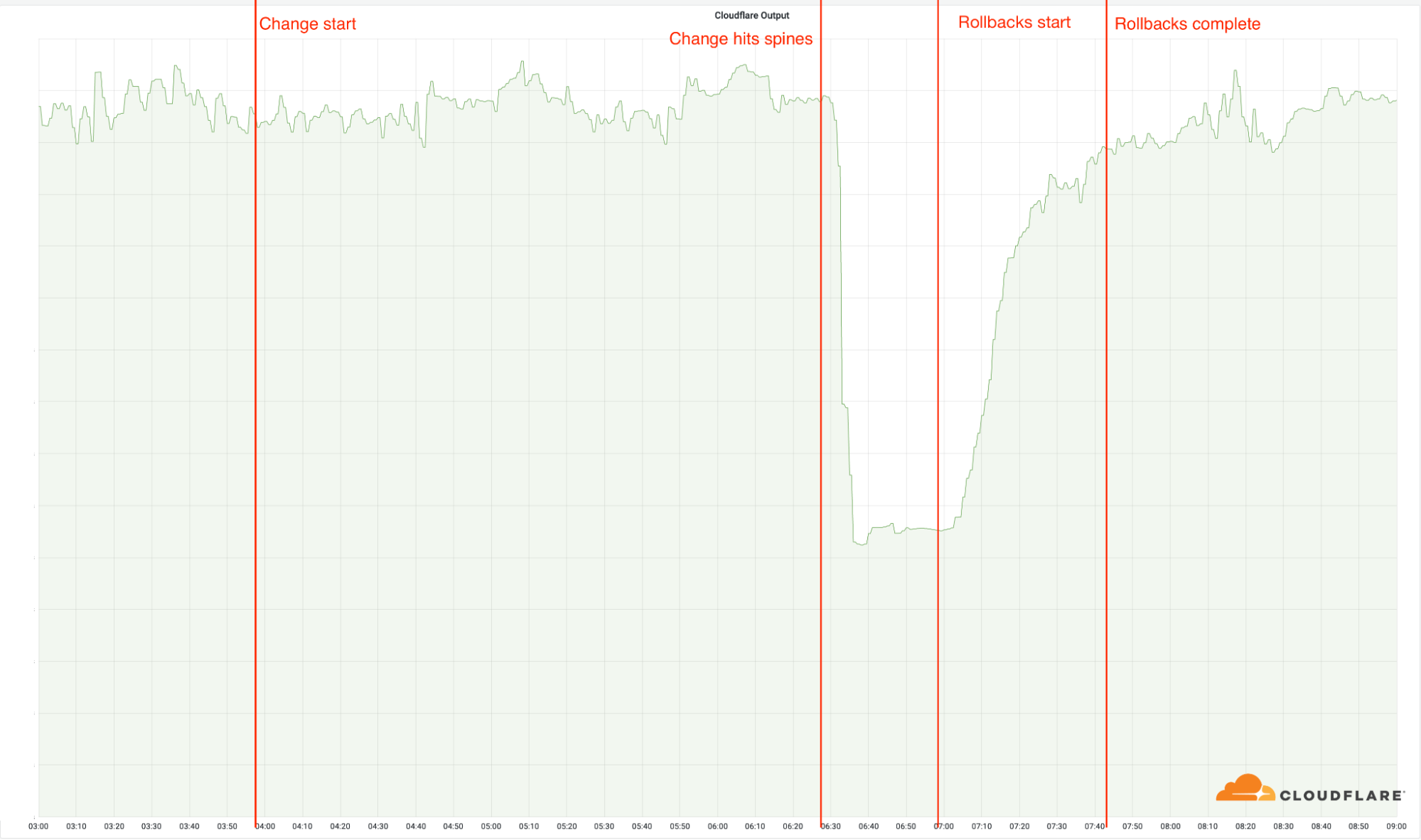
Although only 5% of Cloudflare's network was affected, the outage affected 50% of the total requests, delaying or denying access to the websites for millions of users worldwide, as can be seen in the Cloudflare outbound bandwidth graph:

Despite a massive system outage, Cloudflare was able to quickly find the root cause and perform a service recovery procedure within a couple of hours. According to Cloudflare, the failure began at 06:27 UTC, and by 07:42 UTC all data centres were online and working properly.
Another major outage occurred to one of the largest ISPs in Canada, Rogers Communications, it happened on July 8, 2022 and affected both residential customers and businesses. The nationwide shutdown even affected banks and emergency services (some callers have had difficulty dialling 911). Customers flocked to cafes and public libraries to access alternative networks, while financial institutions reported problems with everything from ATM machines to cashless payment systems. For Rogers, it was the second major outage in just over a year.
Outage was said to be due to an update issue, which Cloudflare data confirms. As seen in the July 8 activity graph, there was a clear spike in BGP updates after 08:15, peaking at 08:45.

A number of consumer and business lawsuits have already been filed against Rogers due to this network outage. One of them is a Class Action lawsuit filed by LPC Avocat Inc. seeking 400 Canadian dollars for every customer who had a contract with Rogers, Fido Mobile, or Chatr Mobile and were not receiving service during the outage. For its part, Rogers offered to compensate customers with a small credit on their next bill. The company first stated that the credit would cost two days of service, and then increased the offer to five days. According to Scotiabank analyst Maher Yaghi, even a two-day credit would end up costing the company more than $65 million Canadian dollars (sources: Financial Post, Reuters).
On July 14, 2022, starting around 1:00 PM CET, tens of thousands of users reported outages on Twitter. The shutdown extended to mobile devices, iOS and Android, and also affected services such as TweetDeck. After about an hour, it was fixed for most users, but only around 5:30 PM CET Twitter released a final update announcing that the issue had been resolved. The platform cited "trouble with the internal systems" as the cause of the outage.
Prior to this, Twitter faced a similar issue also in February, which also lasted for almost an hour.
Google experienced a major outage on August 9th starting at 2:12 AM CET affecting Search and Maps, and issues with search indexing have also been reported.
Users reported that the search engine was down and there were issues with accessing Gmail, Google Maps, and Google Images. Attempts to access these services resulted in error messages, including HTTP 500 (indicates a server-side error that is preventing it from completing servicing the user’s request) and 502 (the web server received an invalid response from an internal server dependency while trying to complete the user’s request) server responses. Google services were fully restored in about an hour.
Most recently, WhatsApp experienced an outage in the early hours of Tuesday, October 25th.
Many users in Europe and other parts of the world have reported that the service was not working: messages were not being sent. The issues were mostly resolved by noon. Other metaservices, including websites and apps for Facebook and Instagram, were not affected, unlike the massive outage that occurred a year earlier.
Due to the lack of service, people ended up switching to sending SMS messages. One of the leaders of the telecommunications market in the Netherlands, KPN, reported that SMS traffic in the period from 10 am to 11 am increased by more than six times compared to the same time the day before!

Several other Fortune 500 tech companies have also faced outage related issues this year. Apple iCloud, Microsoft Azure, and Google Cloud are all among the technology providers who faced service disruptions in 2022, which impacted their business continuity.
To quickly estimate the probable downtime cost, a formula based on the size of the business and the number of minutes the incident lasted is often used:
Downtime cost = minutes of downtime x cost per minute
The larger the size of a business, the greater the cost per minute of downtime. For example, according to Carbonite this value for small businesses may vary from $137 to $427 per minute. For medium and large companies, this value can be thousands and tens of thousands of dollars per minute. According to the Ponemon Institute, on average, the cost of a minute of outage is $900, while the most expensive outages cost $17,000 per minute.

According to ITIC 2020 Global Server Hardware, Server OS Reliability Report (page 31), 25% of respondents said that the average cost of one hour of downtime in terms of lost profits is between $301,000 and $400,000, and hourly downtime costs exceed $300,000 for 88% of companies.

For the near future, teams in charge of managing critical network infrastructure are likely to continue to be challenged by increasing complexity caused by the exponential increase in the number of connected devices and sensors, and which has been further exacerbated by full-scale deployment of 5G networks, network virtualisation, and software defined networking,
On one hand, more frequent and more complex outages will continue to happen until a more resilient infrastructure can be built to meet the growing demand for bandwidth.
On the other hand, given that there are delays in infrastructure expansion around the world, as well as the slow implementation of 5G networks, this gives companies the possibility to better prepare their networks and their monitoring for the full operational launch of 5G.
In practice, expressed by examples shown above, outages can happen even to the best telecommunication providers. Accordingly, everyone should be prepared for incidents and have appropriate procedures to assure the quality of their services. Redundancy, real-time monitoring of the service quality, competent customer support teams, robust change management procedures, and timely maintenance are all viable routes to reduce the risk of downtime.
But the best solution is to be aware and proactive, and to use Plan B only as a last resort in the worst case scenario. The idea is to be able to spot the issues brewing in your networks as early as possible and before they end up impacting (even slightly) the quality of your services.
Being proactive in an environment which produces billions of data points a day is no small challenge. Some would say it's impossible. There is simply too much data to handle. Hence when an outage occurs, typically teams of engineers start diving into the large “black box” of data that has been preserved specially for such an emergency, to then pinpoint and mitigate the root-cause.
For regular daily monitoring, Network Operators reserve their efforts to monitor if customers are complaining, and if their deterministic rules-based alarm systems are picking up the predetermined patterns or any thresholds that have been exceeded.
This becomes even more challenging when there are millions of regular alarms occuring on a daily basis, such a situation is suboptimal but not severe enough to disrupt the service to a point where business continuity is impacted. Examples could be optical power alarms/routing errors, most of which are caused by misconfigurations or human error during implementation. Finding the root-cause of an incident which is being obscured by other more “tolerable” issues requires decades of experience and strong intuition.
An analogue to this issue is good house-keeping practices. If you stop cleaning your house, and you loose your keys, finding them in the mess becomes a daunting task. But if we maintain our house with regular cleaning, the keys shouldn’t take longer than a minute to find! And that’s where AI comes in to the picture. We need a “Roomba” to keep our networks tidy and clean. The tireless robot which can detect all sub-optimal behaviour autonomously and proactively. The skilled assistant which can help us clean up our mess. And if an Operator does end up “losing their keys” (i.e. service is impacted), it shouldn’t be too hard to find them “reactively” since you now know about all the problems that they typically run into. A clean network is a happy network!
At OPT/NET, we have developed the AIOps driven platform OptOSS AI - an AI platform capable of dealing with ever-increasing volumes of data and network complexity! This is our skilled network cleaning robot you can rely on and use to make sure your network stays proactively clean!
OptOSS AI is a platform for monitoring, analysing, and managing complex networks in real time that is able to detect both known and unknown anomalous patterns in your network data autonomously. With OptOSS AI, Operators can rest assured they know exactly what is happening in their network since their tireless helper is not leaving a single line of logs unexamined!
To see our tireless helper in action, watch our online 13 minute demo to see it watching over our lab environment vigilantly!
Send an Email to sales@opt-net.eu 📧to get a personal 🔥 Live Demo 🔥 and find out how OptOSS AI can help you achieve operational excellence for your business!
.png)


{kind=link}